
Filip Hristov
Projektziele, Problemstellung und technische Realisierung
Das Hauptziel des GeldKunstNetz Projekts war die Digitalisierung und eine Online-Edition der 16 Rechnungsbücher der Kaufmanbankiersfamilie Loitz, die eine möglichst nahe Wiedergabe der Originaltexte in digitaler Form und eine Analyse der erhobenen Daten gewährleisten würde. Darüber hinaus stellte sich das Projekt die Aufgabe der Identifizierung in den Quellentexten einzelner im Hinblick auf die Analyse relevanten Entitäten (Personen, Orte, Objekte) und deren strukturierte Modellierung in der Datenbank.
Im Hinblick auf den großen Umfang der Quelle (16 Archivalien mit insgesamt 969 Seiten) war die Festlegung einer klaren Vorgehensweise bei der Textbearbeitung und Textspeicherung notwendig. Für die Bearbeitung und Speicherung der Quellentexte wurde eine nachhaltige Arbeitsplattform eingerichtet, die die festgelegte Arbeitsweise, Workflow, sowie eine parallele Ausführung einzelner Arbeitsschritte und die Arbeitskoordination zwischen den Projektmitarbeiter*innen ermöglichte.
Alle erhobenen Daten werden in einer relationalen Form in eine MySQL Datenbank auf einem Server der LMU gespeichert. Als Projektplattform wurde eine WordPress-basierte Website zur Verfügung gestellt. Für die Textannotation wurde ein von dem DHVLab entwickeltes Werkzeug Namens Squirrel verwendet.
Die Auswahl der Webtechnologien basierte auf der existierenden Infrastruktur, dem Know-How und der Erfahrung der ITG (IT Gruppe Geisteswissenschaften). Die ITG, eine Einrichtung der LMU, die Geisteswissenschaftler bei der Anwendung digitaler Technologien unterstützt, stellt zahlreiche Werkzeuge und Dienste für Erstellung und Pflege der Website zur Verfügung. Dazu zählen sowohl die Serverinfrastruktur für das Website Hosting und eine Datenbankinstanz mit vorhandenen Kommunikationsschnittstellen (PHPMyAdmin) als auch das Transkriptionswerkzeug Squirrel.
Im Folgenden werden einzelne Schritte der IT-Infrastrukturentwicklung, von der Konzipierung bis zu der technischen Umsetzung einzelner Komponenten erklärt.
Zusammengefasste Arbeitsweise
Die Edition erfolgte in folgenden Arbeitsschritten:
- Die Digitalisierung der Archivalien als Scans im TIFF-Format (300 dpi bei Originalgroße).
- Transkription der Quellentexte in einem Worddokument in tabellarischer Form um die Strukturierung des Originals wiederzugeben.
- Edition der Quellentexte nach festgelegten Editionsrichtlinien.
- Import jedes fertigtranskribierten Buches in das Squirrel Transkriptionswerkzeug, wo die Annotation und Tagging einzelner Textelemente (Entitäten) erfolgte.
- Während der Annotationsphase im Squirrel werden die für die Quellenanalyse relevanten Personen, Orte und Objekte identifiziert und in der relationalen GeldKunstNetz-Datenbank als Datenbankentitäten hingelegt und mit einer eindeutigen ID versehen. Dieses Vorgehen ermöglicht eine genaue Identifizierung der Personen, Orte und Objekte, die in den Quellen vorkommen.
- Nachdem ein gesamtes Buch annotiert war, wurde es von Squirrel exportiert, die Texte wurden in Tokens segmentiert und anschließend in die dedizierte GeldKunstNetz Datenbank importiert.
- Das importierte Buch wurde auf den GeldKunstNetz-Subseiten „Edition“ dargestellt und die daraus gewonnen Daten auf der Unterseite „digitale Analysewerkzeuge“ visualisiert und allen Nutzern zur Verfügung sowie selbständigen Modellierung der Daten gestellt.
Diese Arbeitsweise ermöglichte die gleichzeitige Bearbeitung mehrerer Rechnungsbücher: Während z.B. Buch#1 in Squirrel annotiert wurde, konnte Buch#2 im Wordformat offline transkribiert werden. Unabhängig davon konnten weitere Projektmitarbeiter*innen die Datenbankentitäten erstellen und edieren, deren IDs für die Annotationsphase benötigt wurden.
Um Verwirrung zu vermeiden: Das Transkriptionstool Squirrel wurde in dem Projekt nur für die Annotation und Tagging des Textes benutzt. Es ermöglich jedoch auch eine vollständige online Transkription. Diese Option wurde in dem Projekt nicht in Anspruch genommen, weil die Transkription im Wordformat vor der Anwendung des digitalen Transkriptionstools fertiggestellt wurde. Der Import dieser transkribierten Texte ins Squirrel hat dennoch den Arbeitsprozess deutlich erleichtert (e.g. keine redundante Transkription und erneute Texteingabe).
Struktur der Rechnungsbücher. Relationale Datenmodell
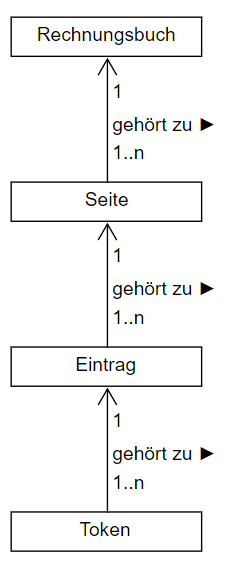
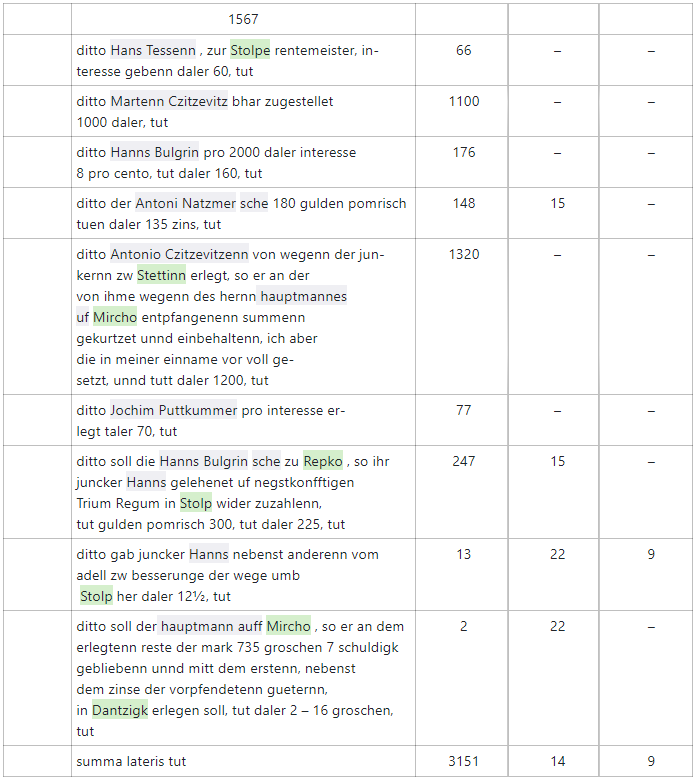
Alle Rechnungsbücher haben gleichartige Struktur: Jedes Buch entspricht einem bestimmten Zeitraum (z.B. Mai – August, 1567) und enthält mehrere Seiten. Jede Seite enthält mehrere Texteinträge, die grafisch durch markierte Zeilen voneinander getrennt sind. Jeder Eintrag ist dreispaltig: die erste Spalte enthält das Datum, die zweite Spalte dsen eigentlichen Eintragstext und die dritte Spalte die Geldsumme der Transaktion, die dann auf drei Spalten für die einzelnen Einheiten (Gulden, Groschen, Pfennige) geteilt ist.
Für die Speicherung des Buchtextes in der relationalen Datenbank wurde der Text in einzelne Wörter segmentiert (Tokens). Jedes Token wird mit bestimmten Attributen beschrieben, die von den Tags und Attributen aus dem Squirrel-Export abgeleitet werden.
Um ein Buch relational zu speichern, berücksichtigend dass ein Buch mehrere Seiten und eine Seite mehrere Einträge enthält, schließlich ein Eintrag aus mehreren Tokens besteht, wird das folgende Datenschema verwendet:
Digitalisat

Tokenisierte digitale Edition
Quellentranskription, -bearbeitung und -speicherung
Für die Transkription und Annotation der Texte wurde Squirrel benutzt. Squirrel ist ein webbasiertes Transkriptions- und Annotationswerkzeug..
Die Arbeitsoberfläche ist zweispaltig: Links wird das Digitalisat dargestellt und rechts der transkribierte Text. Um einzelne Wörter oder Sätze zu annotieren werden verschiedene Tags benutzt, die in der Squirrel Datenbank zur Verfügung stehen. Ferner sind die Tags auch durch den Benutzer editierbar.

Zusätzlich werden die Texte mit weiteren Attributen versehen (getaggt), die erstens die originaltreue Widergabe des Textes ermöglichen (z. B. durch die Markierung der Korrekturen, der durchgestrichen oder hochgestellten Wörter). Zweitens können auf diese Weise die Quellentexte mit Erläuterungen und Kommentaren versehen werden.
Nachdem das gesamte Buch getaggt wurde, bietet Squirrel verschiedene Exportformate: HTML (XLST), PAGE und SQR. Um ein Buch in der relationalen Datenbank zu speichern, wird es als XML Datei exportiert und mit einem Python Skript (GITHUB LINK) in eine CSV-Datei umgewandelt. Das geparste Buch in csv Format wird mithilfe eines WordPress Plugins in der dedizierten Datenbank gespeichert.
Um einen klaren Überblick zu bekommen werden im Folgendem alle Arbeitsschritte am Beispiel eines Bucheintrags präsentiert:

Digitalisat (ein Eintrag von einer Seite):

Transkribierter und annotierter Text (Squirrel):
Exportierte HTML-Repräsentation:
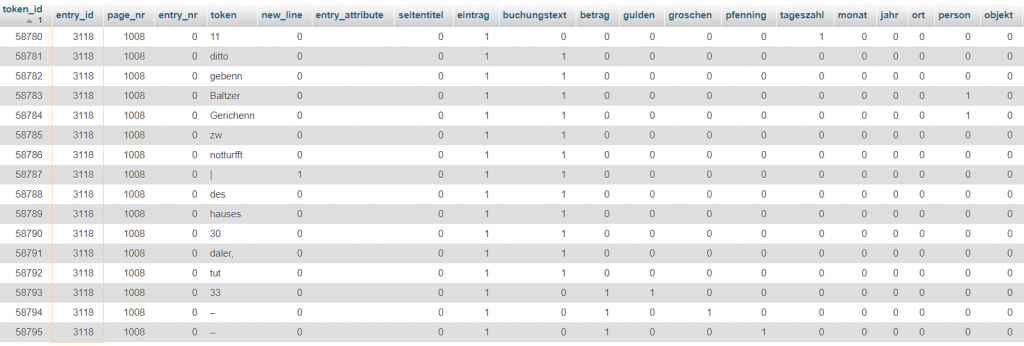
Tokenisierte Version des Textes in der relationalen Datenbank (angezeigt wird nur ein Teil der Attribute):
Visualisierung der digitalen Edition (GeldKunstNetz Webseite):

Datenbank Entitäten und Beziehungen
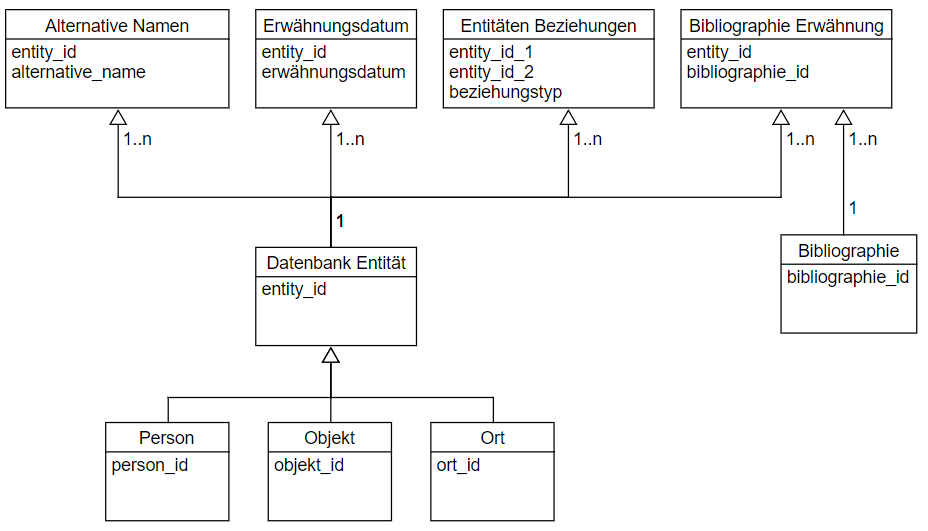
Um die Personen, Orte und Objekte eindeutig in dem Quellentext zu identifizieren und zu taggen, werden Datenbankeinträge mit eindeutigen IDs erstellt. Die Datenbankentitäten verfügen über weitere Attribute, die von den Projektmitarbeitern editiert werden können.
Die Entität wurde im Hinblick auf den Datenbestand und die Fragestellung des GeldKunstNetz Projekts definiert. Dementsprechend werden folgende vier Entitätskategorien eingeführt:
- Person (mit den Attributen: Vorname, Familienname, Beruf, usw.)
- Objekt (mit den Attributen: Objektbezeichnung, Material, Menge, Typ, Funktion, usw.)
- Ort (mit den Attributen: Ortsname, Koordinaten, usw.)
- Bibliographie (mit den Attributen: Titel, Autor, Seiten, usw.)
Die Datenbankentitäten verfügen über weitere quellenspezifische Attribute:
- Erwähnungsdatum: Ein Datum, an dem die betreffende Entität (Person, Objekt, Ort) in der Quelle erwähnt wird. Dies ermöglicht Berücksichtigung der zeitlichen Dimension der Loitz-Tätigkeit.
- Alternative Namen: alternative Schreibweise der Vor-, Familien- und Ortsname der entsprechenden Entität.
- Beziehungen: Relationen zwischen zwei Entitäten. Jede Relation ist als eins-zu-eins Beziehung durch die Art der Beziehung beschrieben. Weitere optionale Merkmale einer Beziehung sind ihr Start- und Enddatum.
Solche Struktur der Entitäten und ihrer Attribute ermöglicht eine weitere Datenanalyse in Form der graphischen Visualisierung. Das Versehen der Entitäten mit den Beziehung-Attributen macht die Identifizierung der komplexen, auch indirekten Beziehungen und Zusammenhänge zwischen mehreren Entitäten möglich.
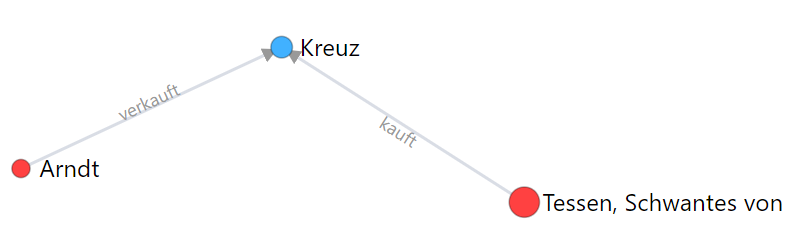
Ein konkreteres Beispiel der Relation zwischen Entitäten sieht folgendermaßen aus:
Visualisierung der Beziehung zwischen zwei Personen die durch die Transaktion des An- bzw. Verkaufs eines Kreuzes in einer Relation standen:

Die Entitäten, die Teil dieser Beziehung sind:


Diese Informationen werden als Graph dargestellt:
Datenanalyse und Visualisierung
Neben der strukturierten Speicherung des digitalisierten Quellentextes war die Datenvisualisierung als Werkzeug der Datenanalyse eines der wichtigsten Ziele des GeldKunstNetz-Projekts. Die Geldkunstnetz Webseite bietet zwei Visualisierungswerkzeuge an, die der Nutzer selbst nutzen kann, um die Daten zu modellieren:
1. Interaktiver Graph mit Such- und Filterfeldern:
Die Graph-Visualisierung dient der Erkennung der Muster innerhalb der Beziehungen zwischen Personen und Objekten. Die Filterfunktion ermöglicht die Spezifizierung der Anfrage.
Bei der Graph-Visualisierung stehen Personen und Objekte im Fokus. Sie werden als skalierte Knoten, abhängig von ihrer Bedeutung (Häufigkeit der Erwähnung in der Quelle) dargestellt. Die Beziehungen zwischen zwei Personen oder einer Person und einem Objekt werden durch Kanten zwischen den Knoten dargestellt. Die Beziehungsart wurde anhand der am häufigsten in der Quelle vorkommenden und für die Fragestellung des Projekts relevanten Relationen festgelegt.
2. Georeferenzierte Visualisierung
Auf der georeferenzierten Karte werden Orte (Städte) als Knoten angezeigt, die in der Quelle vorkommen. Die Größe des Knotens entspricht der Anzahl der im Zusammenhang mit jeweiligen Ort erwähnten Personen. Beim Anklicken des jeweiligen Ortes werden diese Personen in einem Fenster angezeigt.
Webseitebeschreibung
Das WordPress Framework bietet die Möglichkeit die strukturierte Herangehensweise in eine Webseite einzubauen. Dies wird durch Themes und Templates für die graphische Oberfläche der Webseite und Plugins für die Funktionalitäten in einzelnen logischen Komponenten ermöglicht.
Die Hauptfunktionalitäten der GeldKunstNetz-Webseite sind in einem selbstentwickelten Plugin definiert. Die Funktionalitäten der Webseite sind in Subseiten unterteilt, d.h. hede Subseite beinhaltet eine bestimmte Funktion des Plugins (Edition, digitale Analysewerkzeuge).
WordPress als Content Management System (CMS) ermöglicht eine einfache Erstellung von Seiten, eine nutzerorientierte Anpassung des Menüs sowie die Verwendung von dem Benutzerlogin. Das Standardbenutzer Management kombiniert mit Plugins für Benutzerverwaltung ermöglicht es, individuell definierte Rechte an unterschiedliche Nutzer zuzuweisen. Es ist darüber hinaus auch möglich die Sichtbarkeit von und den Zugang zu spezifischen Seiten abhängig von den Nutzerrechte zu bestimmen (z.B. einige Seiten sind nur für die Projektmitarbeiter zugänglich).
Technische Implementierung
Die Hauptfunktionalitäten der Website werden durch ein zentrales GeldKunstNetz-Plugin ermöglicht. Dies wird gemäß des Plugin-Standards von WordPress implementiert:
- Backend: Für das Backend wird PHP benutzt.
- Frontend: Für das Frontend wird Javascript, JQuery, HTML und CSS benutzt.
Weitere benutzte Javascript-Bibliotheken:
- D3 für die Graph-Visualisierung
- JQuery für die DOM Manipulation, User Interaktion und Ajax handlers
- Leaflet and Mapbox für die Visualisierung der Geodaten
- Datatables für flexible und funktionsreiche Tabellen in der Visualisierung, sowie Such- und Filterfunktionen
- Bootstrap für den Framework des responsiven Web Designs
Beschreibung einzelne Komponenten
Die Funktionen der Webseite sind auf 5 separate Unterseiten getrennt:
- Edition: Ansicht der transkribierten Rechnungsbücher.
- Visualisierung der Datenbankentitäten: Datenanalyse mittels grafischer Repräsentation der erhobenen Daten. Interaktion mit den Daten durch Such- und Filterbefehle.
- Datenbankregister: eine tabellarische Anzeige der Datenbankentitäten
- Datenbank: eine interne Seite für Projektmitarbeiter*innen für die Erstellung, Edition und Löschen von Datenbankentitäten ermöglicht
- Backend-Import (Bücher, Personen, Bibliographie): eine interne Seite für den automatisierten Import von Datenbankentitäten und den tokenisierten Büchern.
Jede der Seiten hat eine einzelne Template Datei.
Auf jeder Seite wird die entsprechende Funktionalität mir einem Shortcode initialisiert. Der Hauptdatei des Plugin lädt entsprechende Javascripte und CSS Dateien abhängig von dem Template, das jede Seite benutzt.
Nachdem die JS- und HTML-Dateien auf eine Seite geladen werden, werden AJAX Anfragen an den Server geschickt. Der Server hat Action Hooks registriert, die auf jeweilige Anfrage abhängig von den angegebenen Parametern antwortet und die Dateien an den Client JSON schickt.
So werden die Daten von dem Server geladen und die clientseitigen Funktionen ausgeführt:
Abstrakt werden die Seiten folgendermaßen initialisiert:
Edition => Bücher/Token Anfragen => Datenvisualisierung
Datenbank => Personen/Orte/Objekte/Bibliografien anfragen => Datenvisualisierung
Register => Serverseitige Pagination Personen/Orte/Objekte/Bibliografien anfragen => Datenvisualisierung
Datenanalyse => Personen/Orte/Objekte/Bibliografien anfragen => Datenvisualisierung
Edition
Auf der Editionsseite werden alle edierten Bücher in der GeldKunstNetz-Datenbank visualisiert.
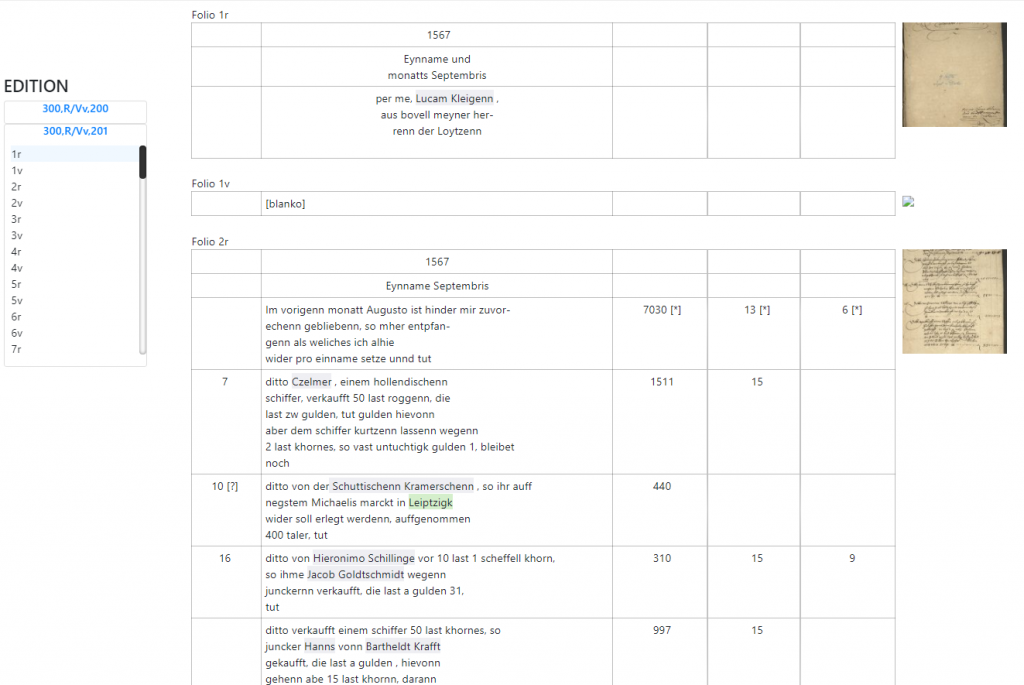
Die Navigation zwischen den einzelnen Büchern und Seiten ist durch ein Dropdown-Menu, auf dem linken Seitenrand ermöglicht. Nach der Wahl eines spezifischen Folios werden Anfragen an den Server geschickt, um die gewünschte Seite und die vor- und nachfolgende Seiten zu laden. Durch den URL-Parameter “book_id” und “folio” ist es möglich, konkrete Folios zu laden und als URL an andere Nutzer zu schicken.
In der Mitte des Seite wird die digitale Edition angezeigt. Das Hauptziel der Edition ist es, eine möglichst originaltreue Visualisierung der Rechnungsbücherstruktur und -inhalt zu gewährleisten. Um die Daten in Tabellen, optisch dem Original entsprechend, darstellen zu können, werden alle Tokens durchgelesen und abhängig von ihren Attributen – werden für jede Seite eines Rechnungsbuchs HTML-Tabellen erzeugt. Jeder Eintrag in dem Rechnungsbuch wird durch eine Spalte der Tabelle dargestellt.
Da jedes Token bestimmte Attribute hat, die als HTML-Klassen und Dataattribute abgebildet sind, ist es möglich die Datenbankentitäten in unterschiedlich Farben zu markieren. Weiterhin sind die Entitäten im Text anklickbar, um weitere Informationen auf dem rechten Seitenrand anzuzeigen.
An dem rechte Seitenrand wird eine Miniatur eines Digitalisats angezeigt. Beim Anklicken kann es sich der Nutzer genau im Vollbild anschauen. Es ist auch möglich mittels des Mausrads das Bild zu vergrößern und per “Drag” zu verschieben.
Datenbankseite
Die nur für die registrierten Nutzer (vor allem Projektmitarbeiter*innen) zugängliche Seite ermöglicht das Erzeugen, Editieren und Löschen der Datenbankentitäten. Zu diesem Zweck werden alle vorhandenen Daten geladen und in Data-Tables angezeigt.
Data Tables ist eine Open Source Javascript Bibliothek, die es ermöglicht Daten in flexible und robuste Tabellen hochzuladen. Jede Tabellenspalte ist durchsuchbar und sortierbar, was die Recherchen und die Übersicht des Datenbestandes erleichtert.
Durch das Anklicken einer Datenbankentitätspalte wird ein Modal mit allen vorhandenen Daten der ausgewählten Entität angezeigt. In dem Modus sind die Daten editierbar und aktualisierbar.
Datenbank-Frontend
Ale Datenbestände des Projekts werden für externe Nutzer nachhaltig zugänglich gemacht. Eine Orientierung und Navigation in dem Bestand ermöglicht die Subseite Datenbank, die als Register gestaltet und damit für den Nutzer ist übersichtlich ist.
Alle Datenbankentitäten (Personen, Orte und Objekte) werden in separaten Tabellen angezeigt. Um das Laden der Daten zu beschleunigen, wird hier eine serverseitige Pagination von den Data-Tables benutzt, d.h. die vorhandenen Daten werden in Teile zerlegt und an den Client teilweise, in Intervallen geschickt.
Digitale Analysewerkzeuge
Die Subseite Digitale Analysewerkzeuge ermöglicht den Zugang zu zwei Werkzeugen der Datenvisualisierung: das erste Tool ermöglich die Beziehungen zwischen den Datenbankentitäten im Sinne einer Netzwerkanalyse als Graphen (mit Knoten und Kanten) darzustellen. Das zweite Werkzeug ist eine georeferenzierte Karte, die in den Quellen vorkommende Orte anzeigt.
Der Graph ist auf der D3 Graphischen Bibliothek basiert. Hier werden mithilfe der Suchmaske Daten von der Datenbank geladen und visualisiert. Die Datenbankentitäten Personen und Objekte sind als Knoten angezeigt, die Beziehungen zwischen den Entitäten sind als Kanten dargestellt.
Damit die Graphen übersichtlich bleiben, werden unterschiedliche Interaktionsmöglichkeiten implementiert. Beim “hovern” (d.h. die Maus über ein gewähltes Objekt bewegen) auf einem Knoten wird die ausgewählte Entität (Person oder Objekt) und alle ihre Beziehungen grafisch deutlicher dargestellt. Es ist weiterhin möglich auf einen Knoten zu klicken, um ausführliche Informationen zu der Entität in einem Pop-up gezeigt zu bekommen.
Die georeferenzierte Karte basiert auf Open Street Maps für die Geodaten und Mapbox für die grafische Oberfläche, d.h. Tiles. Als Javascript Bibliothek wird Leaflet verwendet. Für die grafische Darstellung der Orte als Knoten wird wieder D3 verwendet.
Die Georeferenzierte Karte zeigt alle in den fertig edierten Büchern erwähnten Orte als Knoten. Die Knoten sind anklickbar und zeigen alle Personen, die in Beziehung zu diesem Ort stehen.